

type
Post
status
Published
date
May 8, 2025
slug
summary
tags
知识总结
category
知识仓库
icon
password
语法分析概述
1 语法分析器的作用
从词法分析器获得词法单元的序列,确认该序列是否可以由语言的文法生成。
- 对于语法错误的程序,报告错误信息
- 对于语法正确的程序,生成语法分析树 (简称语法树)

2 语法分析器的分类
- 自顶向下语法分析器 (通常用于处理LL文法)
- 从语法分析树的根部开始构造语法分析树。
- 从文法的开始符号出发,根据文法规则正向推导出给定句子的一种方法。
- 自底向上语法分析器 (通常用于处理LR文法)
- 从语法分析树的叶子开始构造语法分析树。
- 从给定的输入串开始,根据文法规则逐步进行归约,直至归约到文法开始符号的一种方法。
- 两种方法
- 总是从左到右、逐个扫描词法单元
- 只能处理特定类型的文法,但足以描述程序设计语言
3 程序实际语言构造的描述
程序设计语言构造的语法可使用上下文无关文法 (CFG) 或BNF表示
法来描述。
- 文法可给出精确易懂的语法规则
- 可以自动构造出某些类型的文法的语法分析器
- 文法指出了语言的结构,有助于进一步的语义处理/代码生成
- 支持语言的演化和迭代
自顶向下语法分析法
自顶向下的语法分析
为输入串构造语法分析树
- 从分析树的根结点开始,按照先根次序,深度优先地创建各个结点
- 对应于最左推导
基本步骤
- 确定对句型中最左边的非终结符号应用哪个产生式
- 然后对该产生式与输入符号进行匹配
关键问题
- 确定对最左边的非终结符号应用哪个产生式
分析
自顶向下分析就是从起始符号开始,不断的挑选出合适的产生式,将中间句子中的非终结符的展开,最终展开到给定的句子。它的核心思想在于,当我们从左往右匹配这个句子的时候,每匹配一次需要从上往下遍历一次这个 CFG 从而找到合适的产生式,所以被称为自顶向下分析算法。我个人认为这种方法有点类似于 “穷举法”(试错法),因为它的本质是不断的使用产生式规则来发现符合这个句子的语法。
不过自顶向下分析并不是无脑穷举的,当发现某一个产生式产生的终结符和句子的当前结构根本不匹配时,我们就不会再向下继续分析了,因为不管怎么分析也无法得到正确的结果。此时我们就需要回到最近的一次有效的规则,然后继续使用新的规则向后执行,这种行为称为 “回溯”。
说明
非确定的自上而下分析法即是带回溯的自上而下分析法,实际上是一种穷举的试探方法,其分析效率极低,代价很高,在实用的编译程序中是不常用的。我们通常使用确定的自上而下分析法进行语法分析。
但确定的自上而下分析法对语言的文法有一定的限制条件,那就是要求描述语言的文法是无左递归和无回溯的。
例子

LL(1)文法
LL (1) 算法也是一个自顶向下的分析算法,它的定义为:从左(L)向右读入一个程序,最左(L)推导,采用一个(1)前看符号。LL (1) 算法和自顶向下分析算法本质上是一致的,它们的区别就在于 LL (1) 算法使用了一种称为分析表的工具来避免了回溯操作,提高了效率。在现实中,我们可以根据某种 LL (1) 分析器来生成分析表,之后根据分析表来进行语法分析操作,我们可以认为这种方法是一种半自动的语法分析方法。LL (1) 的总体工作方式如下所示:

FIRST
first 集合:对于产生式 x -> β1…βn,
- 如果 β1 是终结符:first (x) = {β1}
- β1 是非终结符,first (x) U= first (β1);
- 如果 β1 属于 nullable,first (x) U= first (β2);
- 如果 β2 属于 nullable,first (x) U= first (β2);

FOLLOW
- follow 集合:follow(后继)字符集合可以看成所有可以合法的站在此非终结符后面的终结符(可能包括结束符 $ 、但不包括 ε )的集合。
可能在某些句型中紧跟在A右边的终结符号的集合
- 例如:S → αAaβ,终结符号a ∈ FOLLOW(A)

Nullable
- nullable 集合:
- 产生式 x -> 空,则 X 属于 nullable 集合;
- x -> Y1…Yn,Y1 到 Yn 都是非终结符且都属于 nullable 集合,则 X 属于 nullable 集合;
SELECT

定义:对文法的任意两个产生式A → α | β
- 不存在终结符号a使得α和β都可推导出以a开头的串
- α和β最多只有一个可推导出空串
- 如果β可推导出空串,那么α不能推导出以FOLLOW(A)中任何终结符号开头 的串
等价于
- 如果ε ∈ FIRST(β),那么FIRST(α) \rap FOLLOW(A) = Φ;反之亦然 (条件三)
当描述语言的文法是LL(1)文法时,可对其进行确定的自上而下的分析。对于非LL(1)文法,可通过消除左递归和反复提取公共左因子对文法进行等价变换。
函数思想:递归下降分析算法


递归下降分析算法使用 “分治法” 来提高分析的效率,对于每一个产生式规则,都应该定义一个自己函数。因为在上下文无关文法中,终结符不可能出现在产生式的左边(可以在产生式左边出现终结符的文法叫做上下文有关文法),上下文无关文法中所有的产生式左边只有一个非终结符。所以我们在调用产生式规则的函数后,就分为两种情况:
- 遇到终结符,因为终结符本质上是 token,所以直接把这个终结符和句子中对应位置的 token 进行比较,判断是否符合即可;符合就继续,不符合就返回
- 遇到非终结符,此时只需要调用这个非终结符对应的函数即可。在这里函数可能会递归的调用,这也是算法名称的来源。
简单来说,就是遇到非终结符就调用函数,遇到终结符就比较。
文法左递归的消除
- 当一个文法是左递归文法时,采用自上而下分析法会使分析过程进入无穷循环之中。
- 对含直接左递归的规则进行等价变换,消除左递归。
- 引进一个新的非终结符,把含左递归的规则改写成右递归。
消除直接左递归(转换为右递归)
- 把左递归式
A -> Aa | b
- 转换为
A -> bA'和A' -> aA' | ε
- 二者的正则式都是
ba*
(以下可以联想线性代数来理解)

例子:


扩充BNF表示法:巴科斯范式
BNF 的全称是 Backus–Naur form,是一种表示上下文无关语法的表示方式。
BNF范式(巴科斯范式)是一种用递归的思想来表述计算机语言符号集的定义规范。
基本结构为 <non-terminal>::=<replacement>
符号表
用途 | 符号表示 |
定义 | = |
串接 | |
终止 | ; |
分隔 | | |
可选 | [ ... ] |
重复 | { ... } |
分组 | ( ... ) |
双引号 | " ... " |
单引号 | ' ... ' |
注释 | (* ... *) |
特殊序列 | ? ... ? |
除外 | - |
- 使用花括号{a}表示符号串a的出现可0次或多次,即表示a*。
- 使用方括号[a]表示a的出现可有可无,它用来表示可供选择的符号串。
- 使用圆括号可在规则中提因子。


回溯的消除
在自上而下分析过程中,由于回溯,需要推翻前面的分析,包括已做的一大堆语义工作,重新去进行试探,这样大大降低了语法分析器的工作效率,因此,需要消除回溯。
避免回溯,对文法的要求:
- 不含左递归(所以要先消左递归
- 同一个非终结符的任意两个候选式的FIRST集不相交(FIRST集详见后文非递归预测分析表的构造
回溯的原因:在文法中,当某个非终结符A有多个候选式时,遇到用A去匹配当前输入符号a时,无法确定选用唯一的一个候选式,二只能逐一进行试探,从而引起回溯。
- 文法中相同左部的规则,其右部左端第一个符号相同而引起回溯。(通过提取公共左因子解决)
- 文法中相同左部的规则,其中某一右部能退出串。
在自上而下分析过程中,为了避免回溯,要求描述语言的文法是LL(1)文法。
非LL(1)文法改写为LL(1)文法:提取公共左因子
回溯的解决方法:提取左公因子(只能减少,不能完全消除)。
思路:使文法每个候选式都有不同的前缀,根据此前缀就可以一次性确定使用哪个候选式而不用回溯。即生成类似这样的文法:
A -> aA | bB,通过匹配a或者b,我们就可以选定使用候选式aA还是bB,失配即为出错而不需要回溯

自底向上分析法
自底向上分析算法是语法分析的另一类重要算法,它包含了 LR (0) 算法、SLR 算法和 LR (1) 算法。自底向上分析算法的主要方式是根据句子的 Token,使用产生式来自右向左进行分析,即把右侧的内容 “收缩” 为左侧的非终结符,这种行为我们称为规约(reduce)。
从左向右对输入串扫描自底向上构造分析树
编译中存在着多种自下而上的分析法,但不管哪种自下而上的分析法都是按照“移进 - 归约”法的原理建立起来的一种语法分析方法。这种分析法的基本思想是用一个寄存文法符号的先进后出栈,将输入符号一个一个地按从左到右扫描顺序移入栈中,边移入边分析,当栈顶符号串形成某条规则右部时就进行一次归约,即用该规则左部非终结符替换相应规则右部符号串,我们把栈顶被归约的这一串符号称为可归约串。重复这一过程直到整个输入串分析完毕。最终若栈中剩下句子右界符“ $ ”和文法的开始符号,则所分析的输入符号串是文法的正确句子,否则,就不是文法的正确句子,报告错误。
下面举例说明这种自下而上的分析过程。
【例 4.11 】设有文法 G [ A ]:
对输入串 abbcde 进行语法分析,检查该符号串是否是该文法的正确句子。
首先设一个符号栈并将输入符号串的左界符“ $ ”移入栈,分析时将输入符号串按从左到右扫描顺序移入栈中,其整个分析过程如表 4.3 所示。

根据可归约串的方式不同,使用不同的算法:
- LR分析法
- 可归约串为句柄
- 优先分析法
- 简单优先分析法
- 算符优先分析法
- 可归约串为最左素短语
算符优先分析法(OPP)
算符优先分析法是一种比较古老的自下而上的语法分析方法,很容易手动推导,但是会有一些问题,现在已经很少使用。现在主流的语法分析技术是 LR 分析法。
定义
假定G是不含ε- 产生式的算符文法。对于任何一对终结符a、b,我们说:
- (1)a等于b当且仅当文法G中含有形如P→ ···ab···或P→···aQb···的产生式;
- (2)a小于b当且仅当G中含有形如P→···aR···的产生式,而R(+=>)b···或R(+=>)Qb···;
- (3)a大于b当且仅当G中含有形如P→···Rb···的产生式,而R(+=>)···a或R(+=>)···aQ;
假定 G 是一个不含ϵ-产生式的算符文法。如果 G 中的任何终结符号对 (a,b)至多只满足下面三种关系之一:
那么就说 G 是一个算符优先文法。
设计思想
已知某个文法,进行算符优先分析需要几个步骤:
- 根据文法构建每个非终结符的 FIRSTVT 集合和 LASTVT 集合。
- 使用 FIRSTVT 和 LASTVT 推导算符的优先关系,构建算符优先表。
- (可选)根据算符优先表,构建优先函数,以替代算符优先表(适合程序实现)。
- 使用算符优先表或优先函数对给定的输入串执行算符优先分析。这一部分实际上是给出了针对输入串的自下而上的归约过程。

检查是否是算符优先文法
算符优先分析法的分析范围仅限于算符优先文法,所以这一步骤是有必要的。
但是,由于是题目所给的文法,在这里可以又省略过这个步骤。
实际上,在进行算符优先关系矩阵的构造时,上述算符优先文法的三条定义都会体现出来。需要我们检查的只是该文法中是否有ε-产生式:显然,该文法是没有ε-产生式的。
素短语
- 句型的素短语是一个短语,它至少包含有一个终结符号,并且除它自身以外不再包含其它素短语。
这种分析算法并不是严格的最左规约,也就是说,每次规约的未必是当前句型的句柄。那它规约的是什么?——最左素短语!!!

- 移进:当栈顶终结符 < 或 = 当前输入符号时。
- 归约:当栈顶终结符 > 当前输入符号时,在栈中寻找最左素短语进行归约。
- 接受:当栈顶终结符 = 当前输入符号=‘#’ 时,分析成功结束。
- 出错:当栈顶终结符与当前输入符号没有优先关系时。
分析:i1+i2*i3
顺序 | 已分析 | 未分析 | 操作 | 解释 |
1 | # | i+i*i# | #<i | 移进i |
2 | #i | +i*i# | i>+ | 归约F→i |
3 | #F | +i*i# | #<+ | 移进+ |
4 | #F+ | i*i# | +<i | 移进i |
5 | #F+i | *i# | i>* | 归约 F→i |
6 | #F+F | *i# | +<* | 移进* |
7 | #F+F* | i# | *<i | 移进i |
8 | #F+F*i | # | i># | 归约 F→i |
9 | #F+F*F | # | *># | 归约T→T*F |
10 | #F+T | # | +># | 归约 E→E+T |
11 | #E | # | #=# | 接受 |
构造FIRSTVT集合和LASTVT集合
FIRSTVT 和 LASTVT 可以和 FIRST 和 FOLLOW 两个集合类比。它们都是非终结符专有的集合,终结符没有。
先来看它们的形式化定义,PP 是任意非终结符。
FIRSTVT
找到文法中以 P 为左部的产生式,看产生式的右部。
- 如果右部是以终结符开头的,就把这个终结符加入 FIRSTVT(P)。
- 如果右部是以非终结符开头的,那么这个非终结符之后跟的一定是一个终结符,否则文法就不是算符文法。不妨设为 Qa⋯,把终结符 a 加入 FIRSTVT(P),同时把 FRISTVT(Q) 中的所有元素也加入 FIRSTVT(P)。
第二条规则实际上是一个递归。也就是说,总会有一个非终结符,它的 FIRSTVT 集合中不含任何来自其他 FIRSTVT 集合的元素。我们最好是从这个非终结符开始求解,然后逐层向上。
LASTVT
和上面一样,找到文法中以 P 为左部的产生式,看产生式的右部。
- 如果右部是以终结符结尾的,就把这个终结符加入 LASTVT(P)。
- 如果右部是以非终结符结尾的,那么这个非终结符之前跟的一定是一个终结符,理由同上。不妨设为 ⋯aQ,把终结符 a 加入 LASTVT(P),同时把 LASTVT(Q) 中的所有元素也加入 LASTVT(P)。
推导终结符之间的优先关系
逐条遍历文法 GG 的产生式右部,结果不外乎以下4种情况:(记得算符文法要求非终结符不能连续出现)
- ⋯ab⋯ 的情况,这时令 a=b。
- ⋯aBc⋯ 的情况,这时令 a=c。
- ⋯aB⋯ 的情况,这时令 a < FIRSTVT(B)中的每个元素(产生若干个二元关系)
- ⋯Ab⋯ 的情况,这时令 LASTVT(A)中的每个元素 > b(同样产生若干个二元关系)
注意上面的几种情况不是互斥的,比如3和4实际上是2的一部分。
为了方便后面的分析,我们需要在文法中添加一个#号,并将其也看做是一个终结符(实际上不是)。在推导优先关系这一步,我们要额外对一个特定的式子 #S##S# 进行推导,其中 SS 是文法的开始符号。这个式子可以对应到上面的234三种情况,都要进行推导。
如此操作下来,我们就得到了一堆终结符(含#在内)之间的二元关系。我们接下来要构建一张优先关系表。
构造优先关系表
有了前一步推导的二元关系,构造优先关系表是十分容易的,就是简单的填表过程。假设我们有 n 个终结符(含#在内),那么优先关系表就是 n*n 的。将这 n 个终结符依次填入表的首行和首列,作为表头。之后根据已经得到的关系依次填表。
做题时,为了和标准答案尽可能接近,最好按照这些终结符在文法中出现的先后顺序来填表头。先出现的先填,后出现的后填。# 一般在最后一个。
需要注意的一点是,对于一个关系对 (a,b)(a,b),其对应的二元关系应该填入表格的第 aa 行、第 bb 列。也就是先看行再看列。
有的格子里可能没有填入任何内容。这是正常现象。这表示两个终结符之间没有优先关系。
- FIRSTVT看横行
- LASTVT看纵行

构造算符优先矩阵
算符优先分析过程
这是最后一步了。我们已经有了对于文法 GG 的优先关系表(或与其对应的优先函数),根据这个表(函数),对于一个特定的输入串,我们就可以执行自下而上的算符优先归约过程。
我们使用一个符号栈 SS,既用它寄存终结符,也用它寄存非终结符。
- 初始化:清空栈,填入#号。在输入串最右边也添加一个#号。
- 从输入串中读入下一个符号。输入串中一定都是终结符,所以读入的符号也一定是终结符。
- 查看栈顶。如果栈顶符号是非终结符,那么就跳过这个符号,再向下看。算符文法的性质规定了此种情况下,下面的符号一定是终结符。
- 比较栈顶符号(准确的说,是栈中最靠近栈顶的终结符,下同)和刚刚读入的符号的优先级。
- 如果栈顶符号的优先级 < 或 = 读入的符号,就执行移进操作,将读入的符号放进栈里。
- 如果栈顶符号的优先级 > 读入的符号,就进入一个循环。找一个临时的变量,用来寄存栈顶的符号(注意如果栈顶是非终结符,就跳过它,找下面的终结符),不妨设变量为Q。向栈的深处查找,每次深入一个符号,如果是非终结符,就跳过。找到第一个优先级 < Q 的符号,停止循环。循环中要同步地更新 Q,即向下深入之前要先将现在位置的符号保存到 Q 中。
- 找到一条合适的产生式,把从找到的优先级 < Q 的那个符号开始直到栈顶的符号串归约为该产生式的左部。注意最下面的符号(也就是最后找到的符号)不参与归约。无论栈顶是终结符还是非终结符,都归约栈顶。归约后的产生式左部留在栈中。
- 回到6开头的逻辑,如果栈顶符号和读入符号之间没有优先关系(这在优先关系表上表现为空的格子),那么出错。
- 重复 2-9 步,直到输入串只剩下一个#号。归约完毕。最后符号栈应该只剩下一个#号和文法的开始符号。
举个例子


LR(k)分析法
LR分析法是一种自下而上语法分析技术,L表示从左到右扫描输入符号,R表示构造一个最右推导的逆过程——最左归约,k表示超前读入k个符号,以便确定归约用的产生式。一个LR分析器由3部分组成:
- 总控程序(驱动程序),对于所有的LR分析器,总控程序都是相同的。
- 分析表:动作表action + 状态转移表goto。
- 分析栈:状态栈和文法符号栈。
LR文法:能够构造一张不含多重入口的LR分析表的文法,即LR分析表的每个入口均是唯一确定的。
LR(k)文法(能用一个每步顶多向前检查k个输入符号的LR分析器进行分析的文法)
- L - 表示从左到右输入串
- R - 表示最右推导的逆过程(即最左归约)
- k - 表示向前看的符号个数
本课程涉及的LR分析法:
- LR(0)
- 0表示不向前看。最简单
- 也最容易产生冲突
- SLR(1)
- 低级LR(1)分析法
- 仅在试图解决LR(0)中产生的冲突时向前看一个符号
- 所以并不能解决所有冲突
- LR(1)
- 始终向前看一个符号
- 解决冲突的能力是此处提及的四者中的最强
- 缺点是自动机状态太多
- LALR(1)
- lookahead-LR
- 合并了LR(1)中的某些状态来简化程序
- 这样的合并是有要求的,并不是所有LR(1)都能变成LALR(1)
- LALR(1)在分析正确串时和LR(1)需要的步骤一样多,在分析错误串时步骤多一些
非LR文法:栈顶内容和输入符号已知时仍无法唯一确定应采取的动作。
取值动作表中规定了4种动作,ACTION[Si,a]表示栈顶状态为 Si 时遇到输入符号 a 应该执行的动作。
LR分析器的逻辑结构

分析栈

LR分析表
给定的上下文无关文法直接构造识别文法所有的规范句型活前缀的DFA,然后再将DFA转换成一张LR分析表。
- 移进action[Si,a]=Sj:将状态 j 进状态栈,a 移进符号栈,输入指针移向下一位置。
- 归约action[Si,a]=rj:用第 j 个产生式 A→β 进行归约,|β|=m ,移去状态栈的 m 个状态和符号栈的 m 个符号,用当前状态栈顶状态 k′ 和 A 查GOTO(k′,A)=t ,将状态 t 移进状态栈,A 移进符号栈,输入指针不动。
- 接受 acc :宣布输入符号串为一个句子。
- 报错 error :状态与文法符号不匹配,宣布输入符号串不是句子。

解释:
- LR分析时有若干个状态(即左侧的0-11
- 在某个状态接收到不同的输入会有不同的操作(包括终结符和非终结符
- 如果接受到终结符,则调用action中的动作
- *s(shift)**表示把输入移进符号栈,后面的数字表示状态转移(把此状态压入状态栈
- r(reduce)表示归约,后面数字表示使用哪一个生成式。所以构造表之前必须把生成式编号,且每个生成式只有一个候选式
- ACC表示接受输入串,即分析成功停止分析
- 空白项表示程序不应该运行到这里,需要报错
- 如果接受到非终结符,则调用goto里面的动作,跳转到指定状态(把对应状态压栈
冲突
冲突类型:
- 移进-归约冲突
- 不知道该移进还是该归约
- 归约-归约冲突
- 同时存在超过一个生成式可被调用归约,不知道使用哪个生成式
两种冲突可同时存在
冲突表现为分析表中的同一个表项包含超过一个动作而导致歧义。
具体冲突的情况要和具体的分析法结合判断。
LR(0)分析
拓广文法
对于文法 G = (VN, VT, P , S ) , 增加如下产生式:S’->S ,其中, S’ ∈ VN∪ VT , 得到 G 的拓广文法,G’ = (VN ’, VT, P ’ , S’ )
其实就是增加了一条右部为开始符号的产生式,就变成了拓广文法
活前缀
将符号串的任意含有头符号的子串称为前缀。特别地,空串ε为任意串的前缀。
采取归约过程前符号栈中的内容,称做可归前缀。
这种前缀包含句柄且不包含句柄之后的任何符号;
【活前缀就是不含句柄之后任何符号的前缀】
对于文法 G = (VN, VT, P , S ) , 设 S’ 是其拓广文法的开始符号(即有产生式 S’-> S), 且α,β∈(VN∪VT)* , ω∈VT。若 S’=^^=>α A ω 且 A ->β, 即 β 为句柄,则 αβ 的任何前缀 γ 都是文法 G 的活前缀。
也就是说可归前缀的所有前缀(包括可归前缀)都是活前缀。
例:文法 G[S] :S -> aAcBe A -> b | Ab B -> d
- 句型abbcde的句柄是b,活前缀有ε, a, ab
- 句型aAbcde的句柄是Ab,活前缀有ε, a, aA, aAb
- 句型aAcde的句柄是d,活前缀有ε, a, aA, aAc, aAcd
规范归约过程中,保证分析栈中总是活前缀,就说明分析采取的移进/归约动作是正确的。
LR(0)项目
对于文法G,其产生式右部添加一个特殊的符号“.”,就构成文法的一个LR(0)项目,简称项目
每个项目的含义是:欲用改产生式归约时,圆点前面的部分为已经识别了的句柄部分,圆点后面的部分为期望的后缀部分。
分类:
- 移进项目: 形如 A -> α • aβ(a∈V
T),即圆点后面为终结符的项目,对应移进状态,把a移进符号栈。
- 待约项目: 形如 A -> α • Bβ,即圆点后面为非终结符的项目,对应待约状态,需要等待分析完非终结符B的串再继续分析A的右部。
- 归约项目: 形如 A -> α •,句柄已形成,可以归约。
- 接受项目: 形如 S’ -> S •。【也是一个归约项目,表示整个句子已经识别完毕】
- 初始项目: 形如 S’ -> • S。
其中a∈VT , α,β∈(VN∪VT)*, A,B∈VT
后继项目: 表示同属于一个产生式的项目,但是圆点的位置仅相差一个文法符号,则称后者为前者的后继项目。
- 的左边是已经归约,右边是没有归约的。
项目集为项目的集合,通常使用方框括起来,并起个名字(编号),如项目集
I0 :
每个项目集表示了一个分析状态,如
I0中的S' -> .E表示S' -> E还没开始分析,而存在生成式E -> aA和E -> bB,他们也没有开始分析,所以就根据项目S' -> .E得到了项目E -> .aA和E -> .bB,他们属于同一个分析状态。如果状态
I0接收输入字符为a,则可以确定此时调用了生成式S' -> E和E -> aA,那么就得到了一个项目E -> a.A,因为存在生成式A -> cA和A -> d,所以E -> a.A和A -> .cA和A -> .d应该是同一个状态(都没有开始分析A)。
重复上述过程,可以得到一个DFA,它的状态集就是LR(0)项目集规范族。
构造识别活前缀的DFA
构造识别文法所有规范句型活前缀DFA的方法:
- 对于构成识别文法规范句型活前缀DFA的每一个状态是由若干个LR(0)项目所组成的集合,称为LR(0)项目集。在这个项目集中,所有的LR(0)项目识别的或前缀是相同的,我们可以利用闭包函数(CLOSURE)来求DFA的一个状态的项目集。

求CLOSURE闭包:

求GO状态转移函数:


构造LR(0)分析表
根据DFA之间的状态转移来构造LR(0)分析表。
规则:
- 分析表左侧的状态即为DFA上的状态序号
- 分析表的goto子表为状态接受非终结符产生的状态转移
- 分析表项为shift的表项为DFA中状态接收终结符产生的状态转移
- 如果某个状态包含规约项目,则此状态在action子表中的所有表项均为此规约动作(因为LR(0)不向前看
LR(0)容易产生冲突:假设某个状态包含项目
A -> a.和项目A -> .c,那么根据规则3,A -> .c应该在action-c那一项填入shift-c操作移进c。但是根据规则4,存在规约项目A -> a.,所以所有action表项应该填入reduce-x,二者产生移进-归约冲突。同样也可能产生归约-归约冲突。SLR(1)分析表
修改LR(0)构造规则4为: 4. 如果某个状态包含规约项目,则action子表中此项目左侧非终结符的follow集的所有表项设置为规约动作
思想:判断是规约还是移进时,向前看一位来试图确定操作
仍然可能存在冲突:如果规约项目左侧非终结符的follow集和移进项目的终结符有交集,则仍然无法通过向前看一位来解决冲突
答题流程
- 拓广文法(切记勿忘
对任意已知文法,假设它的起始符号为S,则添加一个生成式
S' -> S(用来产生接受项目- 把文法转换成每个生成式只有一个候选式的形式并标号(以便分析表中使用标号引用
- 构造LR(0)项目集规范族及其DFA(切记不存在SLR(1)项目集规范族
- 判断LR(0)项目集规范族中是否有冲突(也就是不向前看无法解决的冲突),如果有要写出冲突类型,没有冲突就能构造LR(0)分析表
- 如果存在冲突,冲突是否能通过向前看一位解决。如果能,就可以构造SLR(1)分析表。如果不能,尝试使用后文的LR(1)分析法
LR(1)分析法
基本思想:始终向前看一个符号
LR(k)项目:
[A -> α.β, a1a2...ak],相比LR(0)项目集,后面多了k个符号,表示能出现在A后面的符号(或A后面的符号串的first集)(是A的follow集的子集)。称a1a2..ak为项目的向前搜索符号串。对于LR(1)有效项目,向前搜索符号串的长度为1向前搜索符号仅对规约项目有意义。意为:后续的k个输入符号为
a1a2...ak时才允许此规约的发生如果向前搜索符号串有多个,则使用
/隔开。包含拓广符号
S'的状态为[S' -> .S, $]LALR(1)分析法
构造LR(1)DFA的时候因为向前搜索符号串的不同导致其状态远多于LR(0)DFA
LALR意为lookahead-LR,是一种介于SLR(1)和LR(1)的方法
定义同心集:如果两个LR(1)项目去掉向前搜索符号后是相同的,则称这两个项目集是同心集
LALR(1)思想:合并同心集(和其中的向前搜索符号串)以减少状态数。
可能出现的问题:合并同心集操作可能会产生归约-归约冲突(但是不会产生移进-归约冲突,因为向前搜索符号串只跟归约项目有关
例:存在如下项目集规范族:
I1: {
[A -> c., d]
[B -> c., e]
}
I2: {
[A -> c., e]
[B -> c., d]
}
合并之后得到:
I12: {
[A -> c., d/e]
[B -> c., d/e]
}
那么输入d或e的时候就无法确定分析动作了
实际分析时和LR(1)的区别:
- 如果是正确的输入串,过程一样,只是状态名不同
- 如果是错误的输入串,则LALR(1)的分析速度慢于LR(1),因为合并同心集后做了不必要的规约,导致延迟发现错误
LR(0)-SLR(1)-LR(1)-LALR(1)解题顺序
通常问题:能够构造LR(0)分析表?如果不能,能否构造SLR(1)分析表?如果不能,能否构造LALR(1)分析表(此处要先构造LR(1)分析表)?
- 建立LR(0)有效项目集规范族
- 判断是否存在冲突,如果不存在就可以构造LR(0)分析表,结束
- 冲突是否能通过向前看一个符号解决?如果能,构造SLR(1)分析表,结束
- 构造LR(1)分析表
- 判断合并同心集是否会出现冲突
LL(1)和四种LR文法的关系
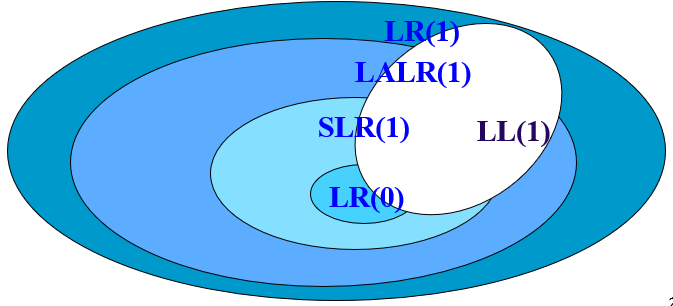
一个文法是LL(1)文法(无二义性、左递归和回溯),它一定是LR(1)文法
参考链接
- Author:Koreyoshi
- URL:https://koreyoshi1216.vercel.app//article/1cac7b13-c6a7-80d7-a926-c4048309e9a5
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!











